量子アニーリングの入口は「研究室」
―量子アニーリングを軸とした研究をされていますが、量子アニーリングに興味をもったきっかけについて教えてください。
朝岡 量子アニーリングに関わる大きなきっかけは、研究室配属です。研究室を決める段階まで量子コンピュータやアニーリングのことについては全く知らなかったんです。研究では、画像解析に携わりたいと思っており、量子アニーリングを使った画像解析についてのお話を工藤和恵先生から聞いたところ、これまでの手法とは異なる手法で画像解析ができることに興味をひかれたので、工藤和恵先生の研究室(以下、工藤研究室)に入ることにしました。
坂倉 私も朝岡さんと同じく、研究室配属がきっかけです。「新しいことに挑戦したい」という思いもあり、色々な先生のお話を聞いていく中で、量子コンピュータやアニーリングマシンについて学べる工藤研究室に興味を持ちました。最適化問題に深い関心があったことも、研究室の決め手のひとつでした。
佐藤 私もふたりと同様に、研究室配属が決まってから、量子アニーリングについて勉強しはじめました。配属以前より、研究では最適化問題を使った交通系の課題解決について取り組みたいと思っていたので、様々な先生に相談していたところ、量子アニーリングを使用した最適化問題について紹介いただき、工藤研究室で研究に取り組みたいと思った次第です。
―研究室への配属がみなさんの量子技術への入り口だったのですね。そこから、2018年度の未踏ターゲットに応募されています。
朝岡 工藤研究室では、もともと組合せ最適化問題や物理シミュレーションなどの分野の研究を行っていたのですが、私たちが研究室に配属された年から量子アニーリングの分野の研究に移行しました。量子アニーリングの研究を新たにはじめた当時は自由に使える実機がなく、そうした事情から、工藤先生より未踏ターゲット事業について紹介して頂きました。
未踏ターゲットのプロジェクトに採択されると、3種類ほどのアニーリングマシンを使え、プロジェクトマネージャーからの指導もいただけます。採択されれば、より有意義な研究ができそうだと思い、応募しました。
―未踏ターゲット事業でのプロジェクトについて、概要を教えてください。
朝岡 坂倉さんと共同で「アニーリングマシンによる画像解析を利用した防犯対策技術」というプロジェクトに取り組みました。概要を説明すると、不審な車両や迷惑行為を行う車両などの特定を想定し、アニーリングマシンで車両のナンバプレートの画像解析を行うというものです。最終的には2種類の画像解析を設けたアプリケーションを作りました。はじめにQBoostという手法で解析にかけ、そこで解析しきれない画像が検出された場合、NBMF(非負二値行列因子分解、以下NBMF)という手法でより詳細な解析を行います。QBoostは坂倉さん、NBMFは私が担当しました。
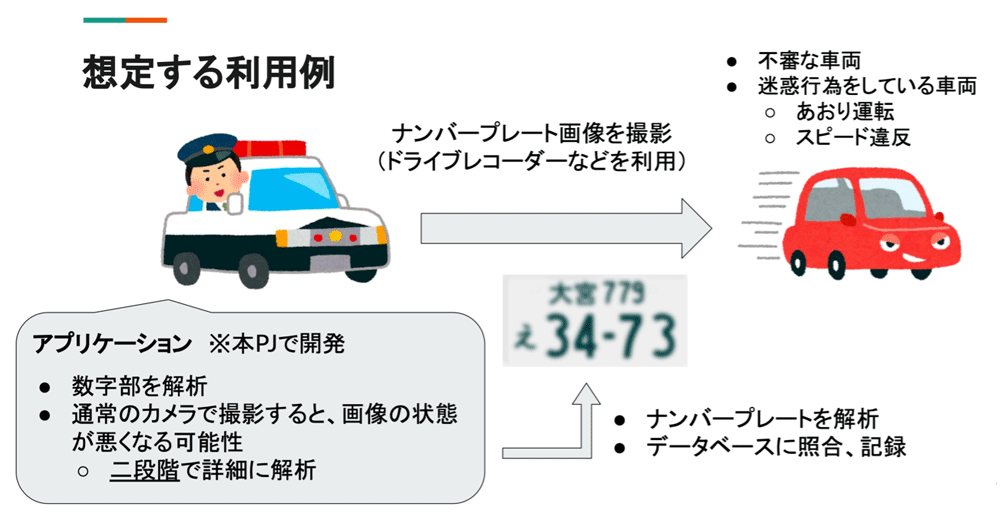 図1. 開発の概要(提供:朝岡氏・坂倉氏)
図1. 開発の概要(提供:朝岡氏・坂倉氏)
佐藤 「アニーリングマシンを利用したライドシェア支援アプリの開発」というテーマで開発を進めました。電車が遅延や運休した時、タクシーに乗る人が増えることで、タクシー乗り場が混雑するのをよく目の当たりにします。そうした時、乗り合いの組み合わせを工夫すれば、問題解決に繋がるのでは?と思ったのが本開発のきっかけです。乗り合いに適したクラスタリング1手法を見つけて関数に落とし込み、その数式をアニーリングマシンで計算することで、ユーザをグループ分けし、配車するというのが開発の概要です。
98%の正解率を出した画像解析手法
―朝岡さんと坂倉さんのプロジェクトでは、2段階に分けて画像解析を行っています。それぞれ、どのような手法で画像解析を行っているのでしょうか。
坂倉 はじめの解析で使用する手法のQBoostは、ブースティングアルゴリズムのひとつです。ブースティングとは、性能の低い識別器2を順番に学習し、組み合わせることでより性能の高い識別器を作るという手法で、機械学習の文脈でよく耳にすることがあるかもしれません。
ブースティングアルゴリズムの中でもよく利用されているものが「AdaBoost」と呼ばれる手法なのですが、こちらは、アニーリングマシンに載せることができません。そのため、アニーリングマシンに対応したブースティングアルゴリズムとして、QBoostを使っています。精度の低い識別器による多数決によって数字の分類を行うのですが、ここではD-Wave量子アニーリングマシンを使用して、訓練データを元に多数決に用いる識別器を抽出しています。
 図2.QBoostの概要 (提供:朝岡氏・坂倉氏)
図2.QBoostの概要 (提供:朝岡氏・坂倉氏)
朝岡 NBMFは行列分解を利用した解析手法です。この行列分解はあるコスト関数の最小化を通じて得られるのですが、そのプロセスをアニーリングマシンで実行しています。そうして分解した行列から、それぞれの画像データについて、ある特徴量を「持っているか持っていないか」についての情報を得ることができます。これらの特徴を各数字の特徴と比較することで、数字の種類を推測します。こちらの図を見ていただくと、イメージが湧きやすいかもしれません。
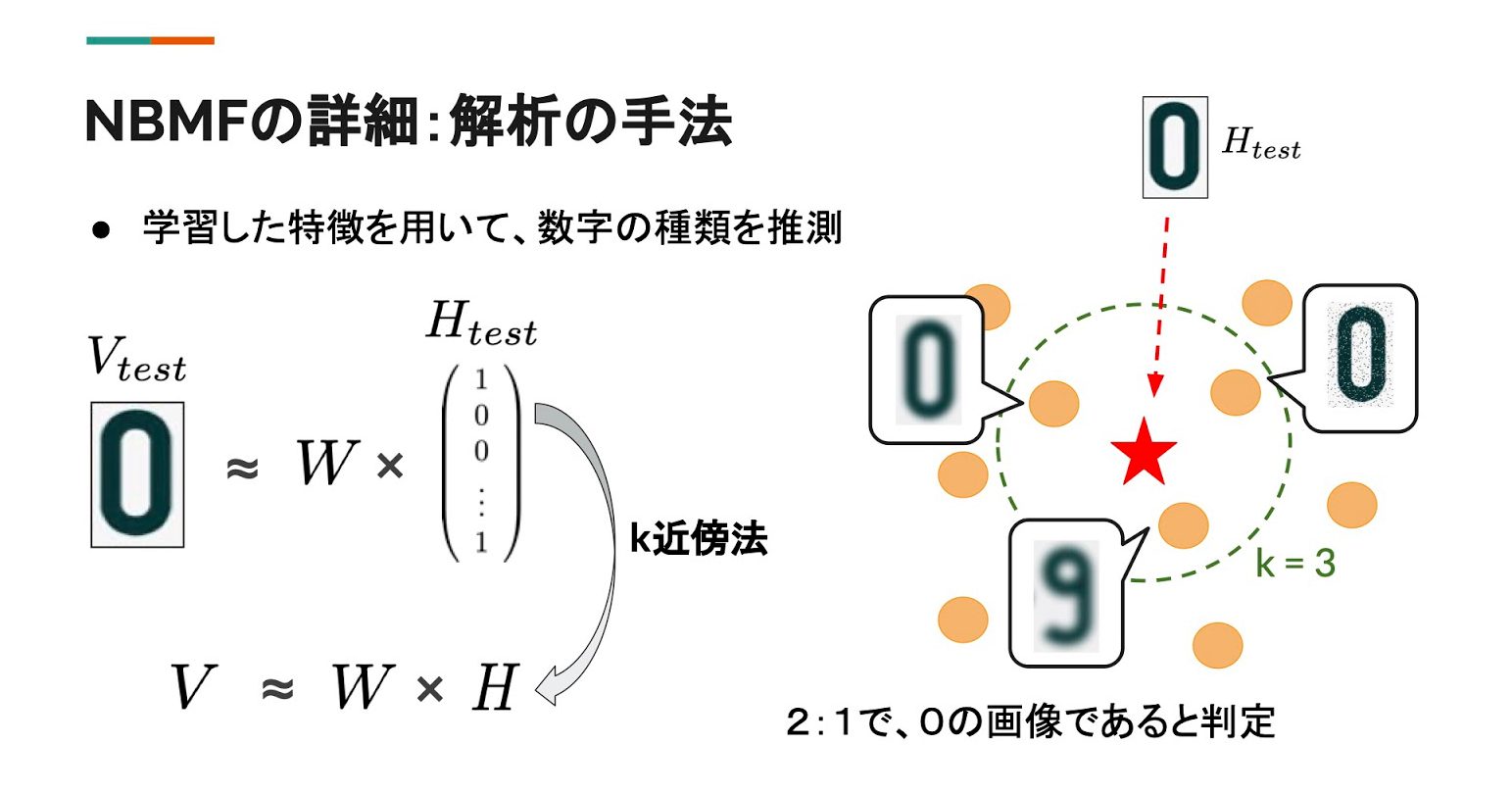 図3.NBMFの詳細について(提供:朝岡氏・坂倉氏)
図3.NBMFの詳細について(提供:朝岡氏・坂倉氏)
訓練データとテストデータで比べた時、テストデータが訓練データと近しい特徴を持っている場合、同じ種類の数字だと判定するというしくみです。この仕組みを取り入れることで,NBMFを利用した数字の判定を可能にしました。NBMFでは、デジタルアニーラ3を使用しています。
最終的にはデスクトップのアプリケーションに落とし込みました。まずQBoost、NBMFの双方の手法で学習データを作り、保存します。2種類の学習データが保存されたら、解析の準備は完了です。ナンバープレートの画像を選択し、解析します。前工程で、すでに保存した学習データを使うため、実際にナンバープレート画像を解析するこの工程では、アニーリングマシンと通信しません。そのため、スムーズに結果が出ます。
―訓練画像から学習データをつくることで、解析時間を短縮できると。
朝岡 開発段階で訓練画像から学習データをつくる段階でかなりの時間を要することに気づいたため、解析するタイミングでは通信を要しない方法を採用しました。開発前の時点では、アニーリングマシンを使うことで画像解析の処理速度が上がると想定していたのですが、実際は訓練画像が多く通信に時間がかかりました。クラウド上からアニーリングマシンを使っていたため、どうしても通信が必要でした。そうした通信データに関する問題は、本開発中に見えた課題でもあります。
―最終的に、どれほどの精度のアプリケーションができたのでしょうか。
朝岡 224枚中221枚の解析に成功しました。精度は98%です。 QBoostのみでも、91%の精度で解析ができたのですが、二段階にすることによって、7%精度をあげることができました。
利用者属性を考慮した配車システム
―タクシーの乗り合いに組合せ最適化を用いていますが、具体的にはどのようにして、グループを分けているのでしょうか。
佐藤 ひとつの出発地からそれぞれの目的地に向かう人たちをグループ分けすることを今回の問題設定としています。また、今回の開発の背景に「性別や年齢などの利用者属性を考慮した相乗りが必要なのでは?」という問題意識があったため、性別や年齢を考慮したグループ分けを行っています。この点は、本開発のひとつのポイントです。最終的には、Webアプリケーションとして落とし込み、利用者と管理者の双方のインターフェースを用意しました。
2段階の計算を経て、ユーザを各グループに分けます。まず、ユーザー数が50人を超える場合、50人以下の集団に分割します。アニーリングマシンを使う際にビット数の制約があることから、今回の開発では、50人以下の集団の分割が必要でした。分割が終わったら、50人以下のユーザーをグループ分けし、それぞれのユーザが乗るタクシーを決めます。ここでは、50人を15台のタクシーに乗り合わせることができ、年齢・性別を考慮した配車を行えたので良い結果が得られました。
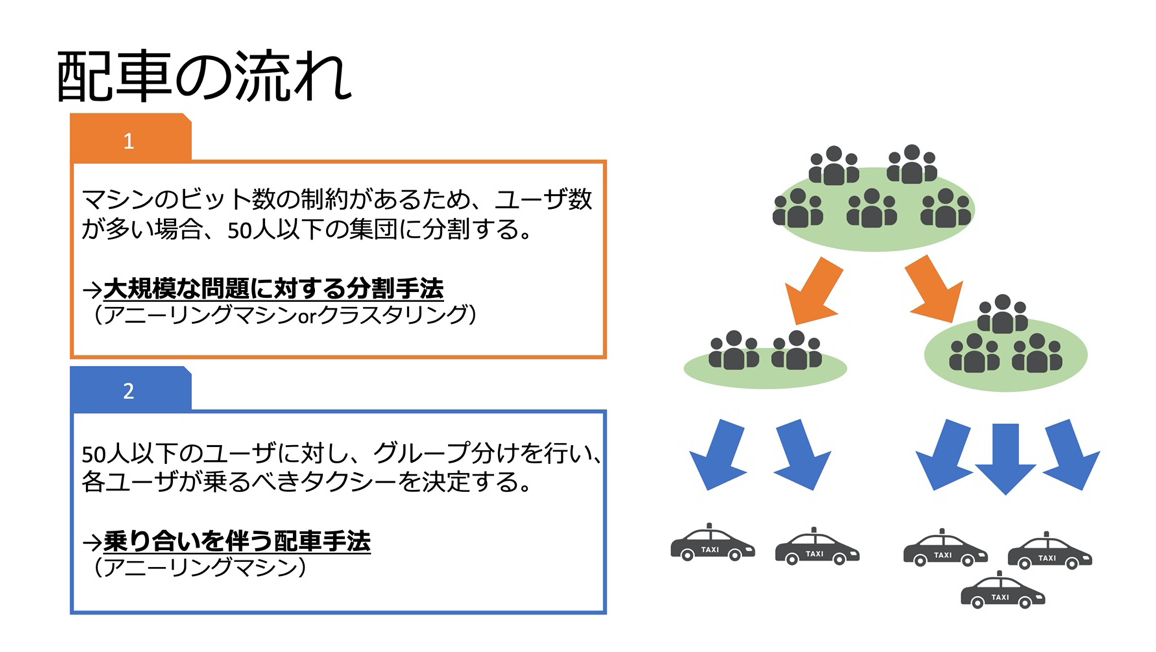 図4.アニーリングマシンを使用した配車の流れ(提供:佐藤氏)
図4.アニーリングマシンを使用した配車の流れ(提供:佐藤氏)
この50人以下のユーザーのグループ分けでは、年齢・性別・直線距離の3つの特徴量に対してそれぞれのユーザーがどの程度似ているかを表す「距離」を定義し、それらの距離が最小化されるときに上手くグループ分けされるようなコスト関数の解をアニーリングマシンで探すという手続きを踏みました。またそのとき、コスト関数にはタクシー一台あたりの定員などの情報も考慮にいれるような制約項を加えています。
 図5. 乗り合いの目的関数(提供:佐藤氏)
図5. 乗り合いの目的関数(提供:佐藤氏)
第一段階で50人以下のグループに分ける時と、第二段階で50人の集団からそれぞれのグループに分ける時の双方でアニーリングマシンを使います。D-wave 2000Q量子アニーリングマシンとデジタルアニーラの双方を使ってみたのですが、使用できるビット数の問題で、今回の問題を解くのに適していたのはデジタルアニーラでしたので、今回開発したアプリケーションでは、デジタルアニーラを採用しています。
また、今回は50人、1000人規模の仮想データを用意し、シミュレーションを行いました。問題に合わせて制約項を設定したり、アニーリングマシンで実行できるよう定式化したりしましたが、この部分は少し大変でした。うまく分割されず、悩むこともありましたが、指導教員や企業の方々に相談することで、解法を見つけられました。
―結果に行き着くまでにも、様々な試行錯誤があったのですね。改良をしていく中で、印象的だったエピソードを教えてください。
佐藤 1段階目の分割方法の検討は、印象的な改良点のひとつです。最初に 2クラスタ分割を思いついたのですが、ひとつの集団をひたすら2つに分割し続ける2クラスタ分割では、離れた人同士が同じグループになる可能性があります。そうした課題の解決策として、プロジェクトマネージャーの田村亮先生(物質材料研究機構)からKクラスタ分割も提案していただきました。そこから、それらの二つを組み合わせた2〜Kクラスタ分割という手法が新たに見出されました。
その結果、最終的には1000人の想定ユーザーの配車結果として、ローカル環境の分割も含めて4つのパターンから配車方法を比較することができました。結果としては、2〜Kクラスタ分割の場合、格段に分割数が増えるため計算時間や使用するタクシーの数も多くなってしまいました。2クラスタ分割にk-means補正4を入れたものだと、計算時間や総移動距離に関しては、2クラスタ分割の場合と大差ありませんでした。計算時間やタクシーの総数、分割におけるリスクなどを加味するとどれも一長一短ではあると思います。
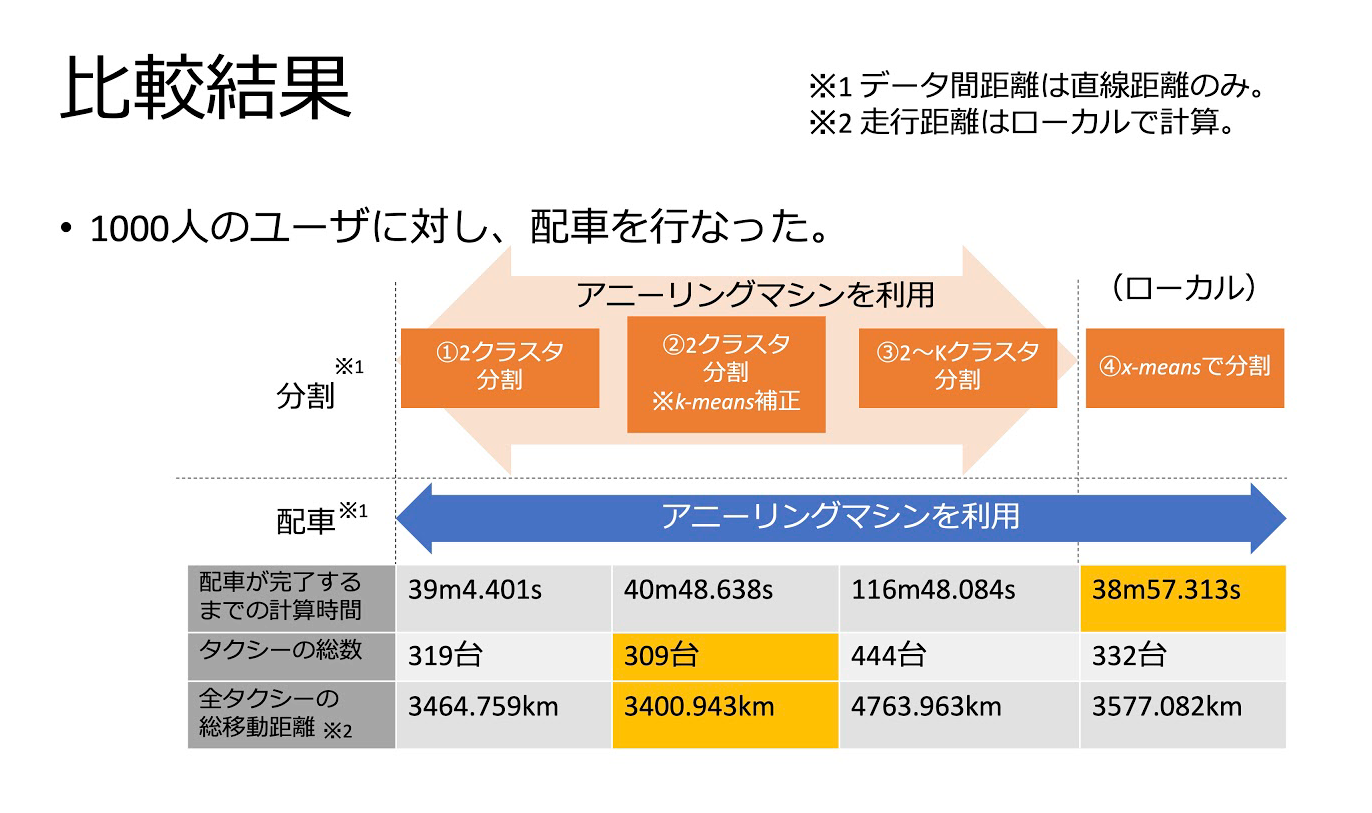 図6. 分割方法による配車結果の比較(提供:佐藤氏)
図6. 分割方法による配車結果の比較(提供:佐藤氏)
プロジェクトを経た感想
―最後に、未踏ターゲットでのプロジェクトを経て感じたことについて教えてください。
朝岡 技術面の指導に加え、プロジェクト期間内での発表や企業へのヒアリングの機会をいただけたことは、ものすごくよい経験になりました。学校の中で研究していると、こうした機会はなかなか得られないと思うので、参加できて良かったです。
坂倉 参加当初は、量子アニーリングマシンを使用したことがなく、ほぼゼロからのスタートでしたが、そうした状態からでも最終的な成果物を出せるまでしっかりと研究をやりきれたこと。また、企業の研究・開発に携わる方々のアドバイスを頂けたことも印象深かったです。「実社会の中で使うアプリケーションだとしたら」という視点での考えも知ることができ、非常に良い経験になったと思っています。
佐藤 私も二人と同様のことを感じています。イジングモデルも知らない状態から、量子アニーリングマシンを使用したウェブアプリケーションの完成まで到達できたことは、自分を成長させたひとつの経験になりました。様々な先生方からのご指導や企業の方々のお話を聞く機会があったからこそ、開発ができたと思います。プロジェクトは私の中でも、大きな成功体験になったので、この経験を自信に変えて、今後も頑張りたいと思います。
(聞き手:田宮志郎、構成・編集:馬本寛子)
※文中図は、朝岡氏・坂倉氏・佐藤氏より「未踏ターゲット事業成果報告会」で使用した資料を提供頂きました。
聞き手

田宮 志郎(たみや・しろう)
東京大学 工学系研究科物理工学専攻に所属。現在、「量子計算機の有効活用へ向けたアルゴリズムの構築およびアプリケーション開発」の研究に取り組む。
- クラスタリング:データをいくつかのグループに分割すること
- 識別器:データを採用するか否かを判断するもの
- デジタルアニーラ:富士通が開発するコンピュータ。「組合せ最適化問題」を得意とする。
- K-means補正:k-means法を使用した補正。データを適当なクラスタに分けたのち、クラスタの平均を用い、データが適度にわかれていくよう、調整させていくアルゴリズムをk-means法と呼ぶ。


コメント
微力ながら量子技術の理解・発展の一助になればと思います。